生物DNA计算机
3.0
2025-01-06
7
4
25.19KB
7 页
10龙币
侵权投诉

No.1 Fugaku( 富岳 ) , 日本 制造商:富士通,处理器核芯:7630848 个;峰值(Rmax):
442010 TFlop/s,
No.2 Summit(美国),美国 制造商:IBM,处理器核芯:2414592 个;峰值(Rmax):
148600 TFlop/s
No.3 Sierra(美国),美国 制造商:IBM,处理器核芯:1572480 个;峰值(Rmax):
94640 TFlop/s
No.4 神威 太湖之光(Sunway TaihuLight)中国,中国 制造商:国家并行计算
机工程技术研究中心,处理器核芯:10649600 个;峰值(Rmax):93015 TFlop/s
No.5 Selene (美国),美国 制造商:Nvidia,处理器核芯:555520 个;峰值(Rmax):
63460 TFlop/s,No.6 TH—2 天河二号(中国),中国 制造商:国防科大,处理器核芯:
4981760 个;峰值(Rmax):61445 TFlop/s
1 DNA 计算的理论、特点和问题
1994 年11 月美国计算机科学家 L.阿德勒曼(L.Adleman)在《科学》
上公布了 DNA 计算机的理论,并成功的运用 DNA 计算机解决了一个有向哈密
尔顿路径问题[1]。这一成果迅速在国际上产生了巨大反响[2],同时也引起了
国内学者的关注[3]。
一些人相信,DNA 计算蕴含的理念可使计算的方式产生“进化”。另一些人则
看到 DNA 计算的理念将有助于揭示生命的本质与演化。总之,这一全新的计算
理论,将在数学与生命科学中产生极其深远而广大的影响。同时它也提出了一
系列值得我们深思的哲学性问题。
DNA 计算机目前尚处在理论研究阶段,一旦它在实用意义上获得成功,DNA
计算将彻底改变计算机硬件的性质。
在过去的半个世纪里,计算机完全就是物理芯片的同义词。但阿德勒曼 DNA
计算机则是一种化学反应计算机[4]。它的基本构想是:以 DNA 碱基序列作为
信息编码的载体,利用现代分子生物学技术,在试管内控制酶作用下的 DNA 序
列反应,作为实现运算的过程;这样,以反应前 DNA 序列作为输入的数据,反
应后的 DNA 序列作为运算的结果。
阿德勒曼具体应用哈密尔顿有向图这个经典 NPC 问题,详细描述了他的理论。
DNA 计算机的提出,产生于这样一个发现,即生物与数学的相似性:①生物体
异常复杂的结构是对由 DNA 序列表示的初始信息执行简单操作(复制、剪接)
的结果;②可计算函数 f(w)的结果可以通过在 w上执行一系列基本的简单函
数而获得。
阿德勒曼不仅意识到这两个过程的相似性,而且意识到可以利用生物过程来
模拟数学过程,更确切地说是,DNA 串可用于表示信息,酶可用于模拟简单的
计算。这是因为:① DNA 是由称作核苷酸的一些单元组成,这些核苷酸随着附
在其上的化学组或基的不同而不同。共有四种基:腺瞟吟、鸟瞟吟、胞嘧啶和
胸腺嘧啶,分别用A、G、C、T表示。
一些单个的核苷酸顺序连在一起形成DNA 链。单链DNA 可以看作是由符合
A、G、C、T组成的字符串。从数学上讲,这意味着我们可以用一个含有四个
字符的字符集∑=A、G、C、T来为信息编码(电子计算机仅使用 0和1这两
个数字)。② DNA 序列上的一些简单操作需要酶的协助,不同的酶发挥不同的
作用。

起作用的有四种酶:a.限制性内切酶,主要功能是切开包含限制性位点的双
链DNA;b.DNA 连接酶,它主要是把一个 DNA 链的端点同另一个链连接在
一起;c.DNA 聚合酶,它的功能包括 DNA 的复制与促进DNA 的合成;d.
外切酶,它可以有选择地破坏双链或单链DNA 分子。
正是基于这四种酶的协作实现了 DNA 计算。
自阿德勒曼用 DNA 计算机解决了哈密尔顿有向图问题,随后很快便有人用
DNA 计算机相继解决了其他一些疑难问题(NPC 完全问题),如可满足性问
题等。与电子计算机相比,DNA 计算机有明显的优势。不过,这些还仅仅是利
用分子技术解决的几个特定问题,是为解决特定问题而进行的一次性实验。
DNA 计算机还没有一个固定的程式。由于问题的多样性导致所采用的分子生
物学技术的多样性,具体问题需要设计具体的实验方案。于是,便引出了两个
根本性的问题,阿德勒曼最早就意识到了它们:① DNA 计算机可以解决哪些问
题?确切地说,DNA 计算机是完备的吗?即通过操纵DNA 能完成所有的(图
灵机)可计算函数吗?②是否可设计出可编程序的 DNA 计算机?即是否存在类
似于电子计算机的通用计算模型——图灵机——那样的通用 DNA 系统(模型)?
目前,人们正处在对这两个根本性问题的研究过程之中。
在我们看来,这就类似于在电子计算机诞生之前的 20 世纪三四十年代——理
论计算机的研究阶段。如今,已经提出了多种DNA 计算模型,但各有千秋,公
认的DNA 计算机的“图灵机”还没有诞生。相对而言,一种被称为“剪接系统”的
DNA 计算机模型较为成功[5]。
由于 DNA 链可以比作在四字符集上的串,为 DNA 计算建模的自然方式就是
利用专门处理字符和字符串的形式语言理论。建模的关键就是要将实际的 DNA
重组抽象为数学上的剪接操作。实际的 DNA 重组,就是在前面所提到的四种
“工具酶”的作用下,对 DNA 链的切割和粘贴的组合过程。
其数学抽象称为剪接操作。大体可做如下描述:给定字符集∑(其元素为符
号)及其上的两个字符串x、y,利用剪接规则r剪接 x和y的过程可以分为:
①在由剪接规则r决定的位置上切割x和y;②分别将结果中 x的前段和 y的后
段、y的前段和 x的后段连在一起。∑ 的剪接规则 r是形如 α1#β1$α2#β2
的词,其中 α1、β1、α2、β2 是∑的串,#和$是∑外的标记符。
我们称 z和w是根据剪接规则r=α1#β1$α2#β2 剪接 x和y的结果,当且
仅当存在∑上的 x1、xƇ、y2、yƈ 使得
x=x1α1β1xƇ, y=y2α2β2yƈ
且 z=x1α1β2yƈ, w=y2α2β1xƇ
并记作(x,y) →(z,w)。
α1β1 和α2β2 这两个串称为剪接位点;x和y称为剪接项。剪接规则r决定
了切割的位点和位置:第一项在α1 和β1 之间,第二项在α2 和β2 之间。值
得注意的是位点α1β1 和α2β2 会分别在x和y中出现多次,如果这样,选择
哪一个位点是不确定的。结果会造成对 x和y剪接的结果是(z,w)的一个集
合。
将剪接操作当作基本工具来构建一种生成机制,便形成了剪接系统。给定一
个字符串集A,A∑*,∑*为字符集∑上由连接操作生成的字符串的集合(∑*中的
元素为串),以及一个剪接现则集R(r∈R∑*#∑*$∑*#∑*),由此所生成

的东西是由如下方法得到的串组成;从集 A开始,在 A和已获得的串上重复使
用剪接规则。
另外,应该说明一点,通常剪接 x和y得到 z和w后,仍可以将 x和y当作
剪接项,与此相似,对新生成的 z和x也没有数量上的限制。但对某些串仅可
使用有限次。故在数学上不用集合来表示剪接项,而用多重集——在每个时刻
都应当记录每个串可用的个数。至此,可以给出剪接系统的一个简洁而又严格
的定义:剪接系统是一个四元组 r=(∑、T、A、R),其中∑是一个字符集,
T ∑是终结字符集,A是∑*上的多重集,R是剪接规则的集合。
定义了 DNA 计算的数学模型后,便可以来回答前面提出的 DNA 计算的完备性
与通用性问题。在计算机科学中,众所周知的丘奇一图灵论点深刻地刻画了任
何实际计算机的计算能力——任何可计算函数都是可由图灵机计算的函数(一
般递归函数)。现已证明:剪接系统是计算完备的,即任何可计算函数都可以
用剪接系统来计算。
换句话说就是,任何图灵机可计算的函数都可以由这种 DNA 计算模型来计算。
反之亦然。这就回答了DNA 计算机可以解决哪些问题——全部图灵机可计算问
题。
对于第二个问题——是否存在基于剪接的可编程计算机——也有了肯定的答
案:对每个给定的字符集 T,都存在一个剪接系统,其公理集和规则集都是有
限的,而且对于以 T为终结字符集的一类系统是通用的。
这就是说,理论上存在一个基于剪接操作的通用可编程的 DNA 计算机。程序
由往通用计算机公理集中添加的字符串组成。程序会有多个,而可利用的公理
集合有无穷多个。这些计算机使用的生物操作只有合成、剪接(切割一连接)
和抽取。
理论上 DNA 计算机具有现代电子计算机同样的计算能力,但它具有的巨大
潜力(功能)却是电子计算机不可比拟的:DNA 计算机运算速度极快,其几天
的运算量就相当于计算机问世以来世界上所有计算机的总运算量;它的贮存容
量非常大,1立方分米的DNA 溶液可以存储 1万亿亿位二进制的数据,超过目
前所有计算机的存储容量;它的能量消耗只有一台普通计算机的十亿分之一。
如此优越的分子计算机当然是激动人心的。然而它离开发、实际应用还有相
当的距离,尚有许多现实的技术性问题需要去解决。如生物操作的困难,有时
轻微的振荡就会使DNA 断裂;有些 DNA 会粘在试管壁、抽筒尖上,从而就在
计算中丢失了。尽管DNA 计算机面对着许许多多的质疑,但它的提出者阿德勒
曼教授依然是极其乐观的:DNA 计算机刚刚提出,尚在胚胎时期,与发展了半
个世纪的电子计算机相比,确实相形见细。
在他看来,提出 DNA 计算机并不就是要与电子计算机竞争。首先,分子计算
的观念拓宽了人们对自然计算现象的理解,特别是生物学中基本算法的理解。
另外,DNA 计算的观念向现有的计算机科学和数学提出了挑战,相信它所蕴涵
的理念可以使计算的方式发生进化。
DNA 计算理论是目前西方发达国家的一个研究热点,有些困难已经通过新
的程序设计技术(无须等待生物技术的发展),采用概率算法及修改数学问题
等传统的解决方案得以解决。
人们大都相信,分子计算的实际应用在未来是可行的。另外,要知道,类似
合成杂交、抽取等所有生物操作的问题,都已被大自然中的生物系统所涉及,

摘要:
展开>>
收起<<
No.1Fugaku(富岳),日本制造商:富士通,处理器核芯:7630848个;峰值(Rmax):442010TFlop/s,No.2Summit(美国),美国制造商:IBM,处理器核芯:2414592个;峰值(Rmax):148600TFlop/sNo.3Sierra(美国),美国制造商:IBM,处理器核芯:1572480个;峰值(Rmax):94640TFlop/sNo.4神威太湖之光(SunwayTaihuLight)中国,中国制造商:国家并行计算机工程技术研究中心,处理器核芯:10649600个;峰值(Rmax):93015TFlop/sNo.5Selene(美国),美国制造商:Nvi...
声明:本站是提供个人知识管理的网络存储空间,所有内容均由用户发布,不代表本站观点。请注意甄别内容中的联系方式、诱导购买等信息,谨防诈骗。如发现有害或侵权内容,请点击侵权投诉。
相关推荐
-
烟气脱硝及催化剂知识10.10
 2024-09-14 78
2024-09-14 78 -
双极制氢

 2024-09-26 89
2024-09-26 89 -
镍锌无隔膜燃料电池简介
 2024-10-05 69
2024-10-05 69 -
附图:计算机监控系统图
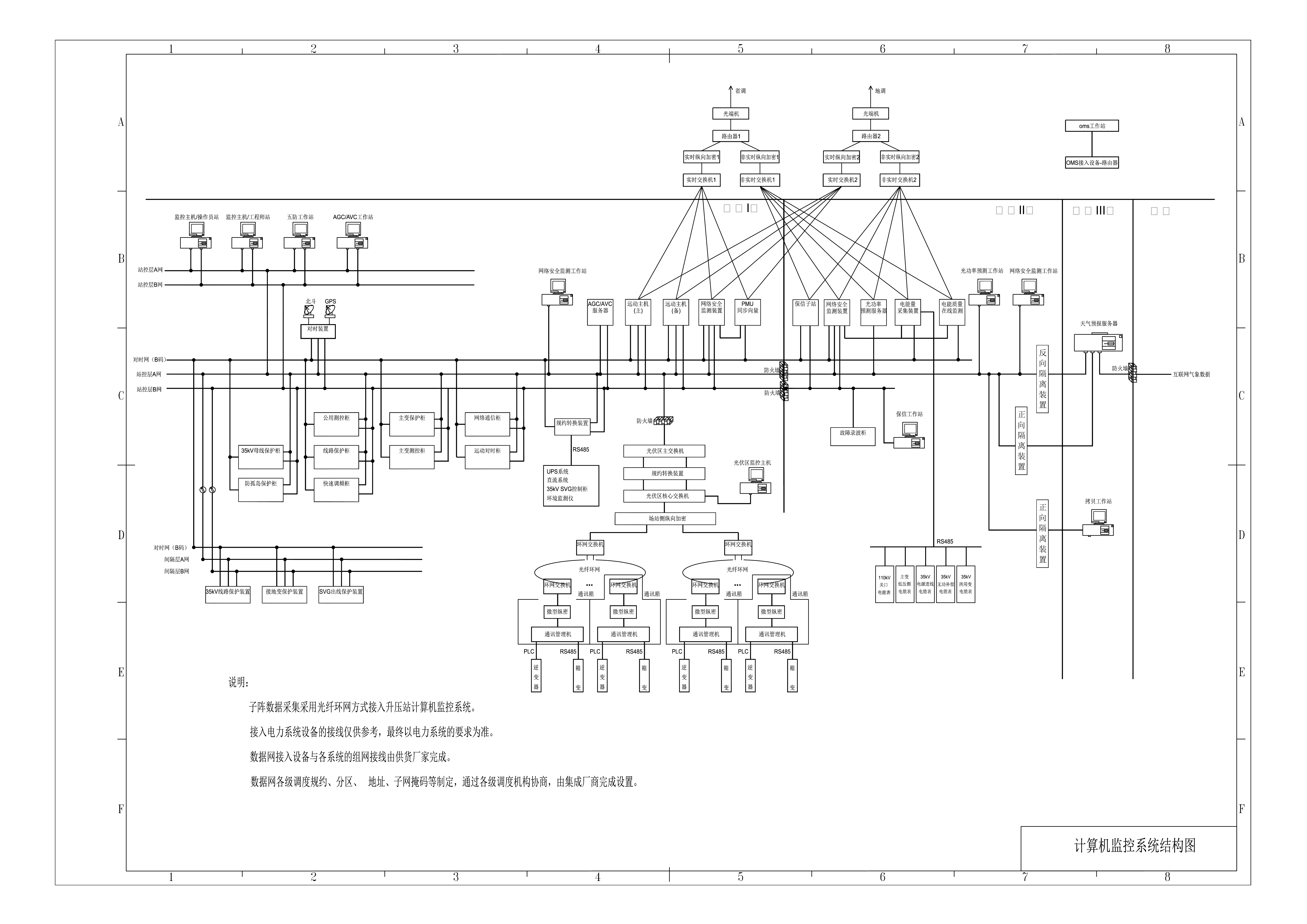
 2024-10-05 118
2024-10-05 118 -
华为防逆流装置讲解
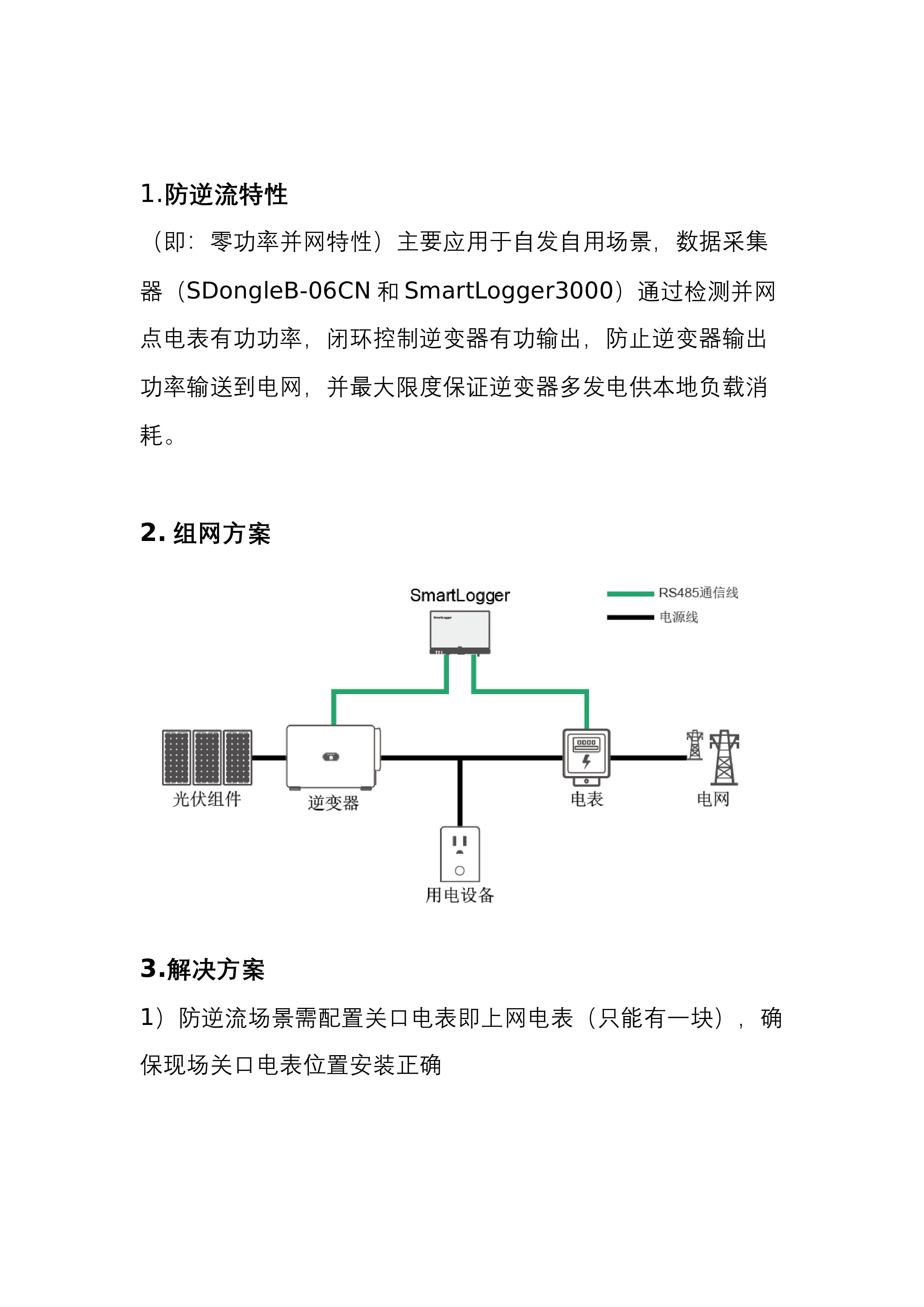 2024-12-03 268
2024-12-03 268 -
2025版+最新强制性条文汇编(2月4日更新)
 2025-02-24 254
2025-02-24 254 -
变压器互为备用研究
2025-03-13 52
-
ESPLAZA长时储能行业月报-2025年2月刊
 2025-03-28 71
2025-03-28 71 -
南方电网公司输变电工程造价控制线(2025 年)
 2025-08-21 254
2025-08-21 254 -
GB+20052-2024 电力变压器能效限定值及能效等级-副本
 2026-04-20 49
2026-04-20 49
分类:实用文档
价格:10龙币
属性:7 页
大小:25.19KB
格式:DOCX
时间:2025-01-06
相关内容
-
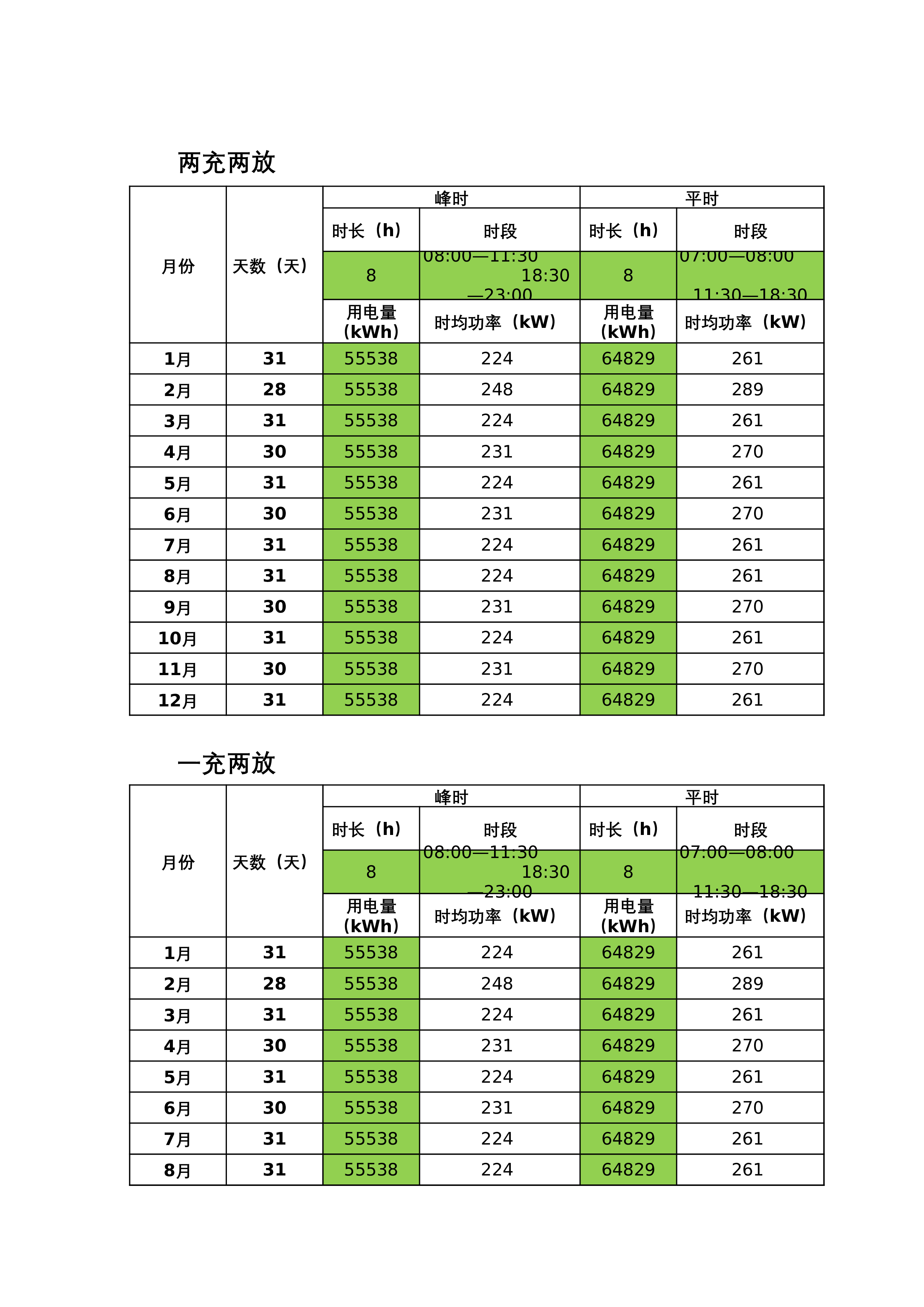
用户侧纯储能容量的测算
分类:实用文档
时间:2026-05-19
标签:无
格式:XLSX
价格:5 龙币
-
04_02_储能电站SCADA 屏柜+原理+供电+端子图-20220414 - 副本
分类:实用文档
时间:2026-05-19
标签:无
格式:DWG
价格:5 龙币
-
110KV储能电站系统技术方案_光伏发电侧储能项目 2.5MW 13.8MWh
分类:实用文档
时间:2026-05-19
标签:无
格式:DOCX
价格:5 龙币
-
储能电站施工图设计(1)
分类:实用文档
时间:2026-05-19
标签:无
格式:PDF
价格:5 龙币
-
用户侧储能电站开发的要点和优势
分类:实用文档
时间:2026-05-19
标签:无
格式:DOCX
价格:5 龙币
 冀公网安备13010802002329
冀公网安备13010802002329
